주제 : 구문 정보를 이용한 인공신경망 기반 문서 검색 기법
오픈 도메인 질의응답 시스템에서는 입력된 문서에서 정답을 잘 찾아주는 것뿐만 아니라 다양한 지식 문서에서 정답을 포함하고 있을 법한 문서를 잘 골라내어 기계 독해 시스템의 입력으로 주는 것 또한 매우 중요한 작업이다.
문서 추출 작업에 신경망 기법을 적용한다면 정확도가 더 상승할 수 있지만 수많은 문서에 대해서 신경망 모델을 적용한다면 매우 오랜 시간이 걸릴 것이다.
이러한 문제를 극복하기 위해, 본 주제에서는 지식 문서인 위키피디아 문서와 사용자의 질문을 잘 표현하는 임베딩을 학습시키고 LSH를 이용하여 질문과 유사한 임베딩을 가지는 문서를 빠르게 검색할 수 있는 시스템을 개발하고자 한다.
필요 기술 키워드
오픈 도메인 질의응답 시스템
[223]기계독해 QA: 검색인가, NLP인가?
[223]기계독해 QA: 검색인가, NLP인가?
www.slideshare.net
Question Answering ( 질의응답 시스템)
위키피디아 그리고 검색을 통해서
medium.com
기계독해 시스템
딥러닝 - 어떻게 해야 기계에게 글을 잘 읽고 말할 수 있게 할까? - 기계독해(MRC)
https://www.slideshare.net/NaverEngineering/ss-108892693 기계독해(Machine Reading Comprehension)에 대해 설명한 자료입니다. 대표적인 벤치마크로 SQuAD(Stanford Question Answering Dataset)를 들 수 있는데요. 다음과 같이 지�
aidev.co.kr
인공 신경망 기법
인공 신경망 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 인공 신경망은 노드들의 그룹으로 연결되어 있으며 이들은 뇌의 방대한 뉴런의 네트워크과 유사하다. 위 그림에서 각 원모양의 노드는 인공 뉴런을 나타내고 �
ko.wikipedia.org
[머신 러닝/딥 러닝] 인공신경망 (Artificial Neural Network, ANN)의 종류와 구조 및 개념
그림으로 보는 인공신경망의 종류 및 구조 그림 1은 다양한 인공신경망 (Artificial Neural Network, ANN)의 종류와 개념을 시각적으로 보여주며, 원본 그림은 The Asimov Institute에서 확인할 수 있다. 이 글��
untitledtblog.tistory.com
임베딩 이란
임베딩이란?
컴퓨터가 바라보는 문자 아래와 같이 문자는 컴퓨터가 해석할 때 그냥 기호일 뿐이다. 이렇게 encoding된 상태로 보게 되면 아래와 같은 문제점이 발생할 수 있다. 이 글자가 어떤 글자인지를 표시
heung-bae-lee.github.io
한국어 임베딩 · ratsgo's blog
임베딩(embedding)은 자연어를 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련의 과정 전체를 가리키는 용어입니다. 단어나 문장 각각을 벡터로 변환해 벡터 공간에 ‘끼워 넣는다(embed)’는 취지에�
ratsgo.github.io
LSH
Locality-sensitive hashing - Wikipedia
In computer science, locality-sensitive hashing (LSH) is an algorithmic technique that hashes similar input items into the same "buckets" with high probability.[1] (The number of buckets are much smaller than the universe of possible input items.)[1] Since
en.wikipedia.org
Random Projection and Locality Sensitive Hashing
k-nearest neighbor (k-NN) 문제는 모든 query 와 reference data 의 모든 점들 간의 거리를 계산하기 때문에 많은 거리 계산 비용과 정렬 비용이 든다고 알려져 있습니다. 하지만 approximated nearest neighbor search (
lovit.github.io
목차
- 기술소개
- 인공신경망 기법
- 자연어(한국어 처리)
- LSH 알고리즘
- 임베딩
- 오픈 도메인 질의응답 시스템
- 기계독해
- 개발환경
- 개발 언어
- 개발 도구
- 대상 시스템
- 시스템 구성도
- 주요모듈
- 검색엔진
- 텐서플로우
- 딥러닝 기반 자연어 처리 모듈
기술소개
1. 인공신경망 기법

인공신경망은 생물학적 뇌의 작동 원리를 그대로 모방하는 방법으로서, 데이터 안의 독특한 패턴이나 구조를 인지하는데 필요한 모델을 구축하는 기법이다.
노드는 생체 내의 신경세포와 비슷한 것으로서, 가중치화된 상호 연결성으로 서로 연결되어 있다. 가장 일반적인 인공신경망 모형은 아래 그림과 같은 다계층 퍼셉트론 모형으로서, 입력층(input layer)에서 은닉층(hidden layer), 은닉층에서 출력층(output layer)으로 각 노드가 서로 연결되어 있는 것이 특징이다.
인공신경망은 인간의 신경학적 뉴런과 비슷한 노드(node)와 층(layer)으로 구성되며, 노드는 신경망 모형에서 가장 기본적인 요소를 말한다. 노드는 입력물로 받아들여 작동하는 인간의 뇌와 비슷한다. 학습 패러다임에 근거한 인공신경망은 입력 데이터를 기초로 가중치를 통해서 의사결정을 하게 된다.
인공신경망 모형은 예측 오차를 줄이고 예측 정확성을 증진시키기 위해서 반복적으로 가중치를 수정하는데, 이러한 반복적인 단계를 훈련이라고 한다. 인공신경망은 복잡하고 비선형적이며 관계성을 갖는 다변량을 분석할 수 있다. 인공신경망 기법은 회귀분석과 같은 선형 기법과 비교하여 비선형 기법으로서의 예측력이 뛰어나며, 자료에 대한 통계적 분석 없이 결정을 수행할 수 있다. 인공신경망은 통계적 기본 가정이 적고 유연하여 다양하게 활용된다. 특히 데이터 사이즈가 작은 경우, 불완전 데이터, 노이즈 데이터가 많은 경우에 인공신경망 모델의 성능이 일반적으로 다른 기법과 비교하여 우수하다고 평가된다.
그러나, 모델이 제시하는 결과에 대해서 왜 그런 결과가 나왔는지에 대한 원인을 명확하게 설명할 수 없다는 점과, 모델의 학습에 시간이 과도하게 소요되는 점, 전체적인 관점에서의 최적해가 아닌 지역 내 최적해가 선택될 수 있다는 점, 과적합화(overfitting)가 될 수 있다는 점 등이 인공신경망 기법의 단점이라고 말할 수 있다.
일반적으로 데이터마이닝을 사용할 때, 데이터를 훈련용 데이터와 모델의 검증을 위한 테스트 데이터로 구분한다. 훈련용 데이터는 모델을 만드는 데에 사용되는 데이터이고, 테스트 데이터는 모델의 정확도, 예측력을 테스트하기 위해서 사용되는 데이터이다.
2. 자연어 처리(한국어 처리)

자연어(natural language)란 우리가 일상 생활에서 사용하는 언어를 말합니다. 자연어 처리(natural language processing)란 이러한 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일을 말합니다.
자연어 처리는 음성 인식, 내용 요약, 번역, 사용자의 감성 분석, 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류), 질의 응답 시스템, 챗봇과 같은 곳에서 사용되는 분야입니다.
최근 딥 러닝이 주목을 받으면서, 인공지능이 IT 분야에서 중요 키워드로 떠오르고 있습니다. 자연어 처리는 기계에게 인간의 언어를 이해시킨다는 점에서 인공지능에 있어서 가장 중요한 연구 분야이면서도, 아직도 정복되어야 할 산이 많은 분야입니다.
이 책에서는 자연어 처리에 필요한 전처리 방법(preprocessing), 딥 러닝 이전에 주류로 사용되었던 통계 기반의 언어 모델, 그리고 자연어 처리의 비약적인 성능을 이루어낸 딥 러닝을 이용한 자연어 처리에 대한 전반적인 지식을 다룹니다.
3. LSH 알고리즘 : Locality Sensitive Hashing
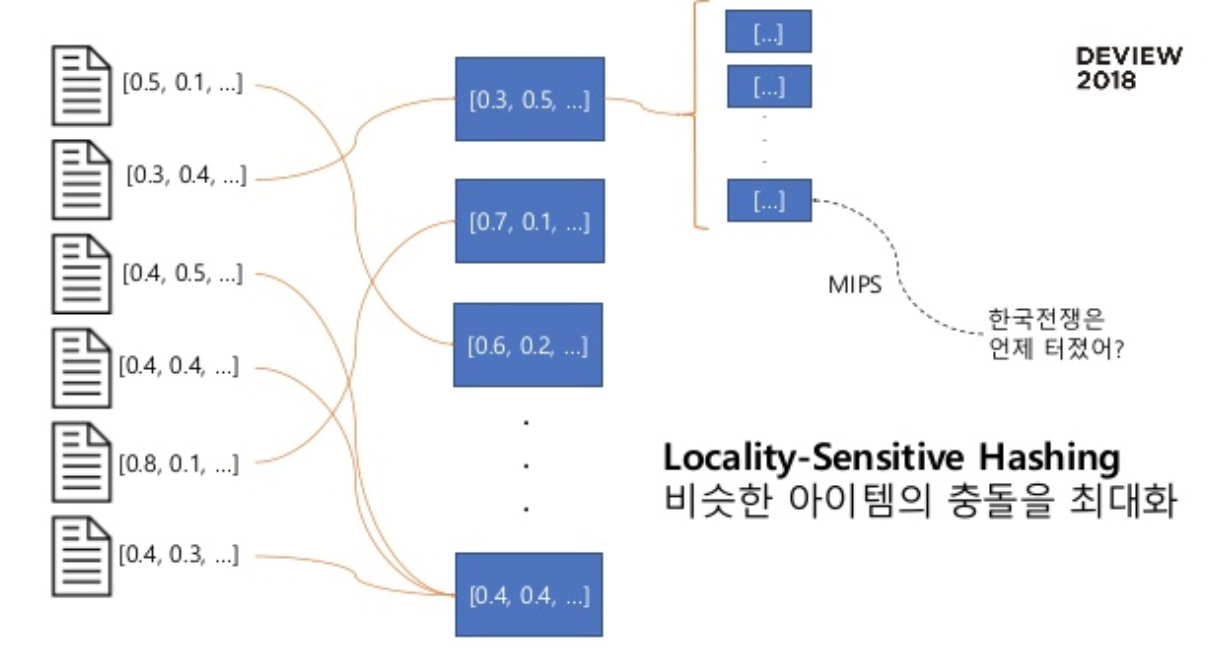
Locality Sensitive Hashing 은 hashing 기반 방법으고 가장 널리 이용되는 ANNS(Approximated nearest neighbor search)이다. 정확한 k개의 최인접이웃을 찾는게 아닌 비슷한 최인접 이웃을 빠르게 찾기 위한 방법이다. 벡터 공간을 단순한 공간으로 분할해서 이해하는 vector quantization을 사용하고 hashing 기반 방법인 LSH가 가장 널리 이용되는 방법이다.
Locality Sensitive Hashing 은 Random Projection 을 이용하는 Approximated Nearest Neighbor Search (ANNS) 알고리즘입니다.
4. 임베딩
임베딩이란 자연어를 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련의 과정 전체를 가리키는 용어입니다. 단어나 문장 각각을 벡터로 변환해 벡터 공간에 '끼워 넣는다(embed)'는 취지에서 임베딩이라는 이름이 붙었습니다. 컴퓨터가 장연어를 처리할 수 있게 하려면 자연어를 계산 가능한 형식인 임베딩으로 바꿔줘야 합니다.
임베딩은 컴퓨터가 장연어를 이해하도록 하는 첫 관문으로 자연어 처리 모델의 성능은 임베딩이 큰 역할을 담당한다.
임베딩에는 말뭉치(corpus)의 의미, 문법 정보가 응축돼 있으며 벡터이기 때문에 사칙연산이 가능하며, 단어, 문서 관련도를 계산할 수 있습니다.
5. 오픈 도메인 질의응답 시스템
질의응답(QA)는 구조화 되지 않은 자연어 문서 모음에서 응답을 가져 올 수 있어야 한다.
키워드 추출은 입력 질문 유형을 식별하는 첫번 째 단계이며 질문 유형이 식별되면 정보 검색 시스템을 사용하여 올바른 키워드를 포함하는 문서 집합을 찾는다. 이때 벡터 공간 모델은 후보 답변을 분류하기위한 전략으로 사용될수 있다.
6. 기계독해
기계독해는 주어진 문서와 문서에 대한 질문이 주어졌을 때, 문서 내에서 답을 구하는 문제입니다. 기계독해는 2016년 SQuAD를 시발점으로 최근에 많은 모델과 많은 데이터(TriviaQA, MS MARCO 등등)가 연구 및 공개되었습니다. 기계독해 모델이 QA(질의응답) 엔진에 직접적으로 적용이 가능하기 때문에 연구가 활발히 이루어 지고 있습니다. 예를 들어 "하늘이 왜 파랄까?" 라는 질문을 답하기 위해 먼저 관련된 "하늘"이라는 문서를 찾고, 기계독해 모델에 해당 문서와 질문을 넣게 되면, 답이 나오는 구조입니다. 문서를 찾아주기만 하는 서비스, 즉 "검색"을 넘어서서 문서를 "이해"하고 원하는 정보를 꼭 집어서 찾아줄 수 있는 서비스가 될 수 있습니다. 기계독해를 통한 QA는 검색과 NLP의 첨단 접점입니다.
검색기반 QA는 섬세함이 부족하고 기계독해 기반 QA는 속도가 느린 한계가 있습니다.
개발환경
1. 개발언어 : Python(딥러닝), Kotlin(클라이언트), C++(검색엔진)
2. 개발도구 : PyCharm(딥러닝), Android Studio(클라이언트), Visual Studio(검색엔진)
3. 대상 시스템 : 윈도우PC(서버), 안드로이드PC(클라이언트)
시스템 구성도

주요모듈
1. 검색엔진
[Inverted Index 방식]
index란 key-value 구조를 가지는 테이블을 말합니다.
보통의 Index는 forward index를 의미하는데 어떠한 주어진 Document가 key에 해당하고 Document에 존재하는 Woord들이 value에 해당됩니다.
forward index와 달리, inverted index는 word가 key가 되고, 그 Word 가 존재하는 Document들이 Value가 됩니다.
인덱싱을 하기 때문에 탐색 속도가 매우 빠릅니다.
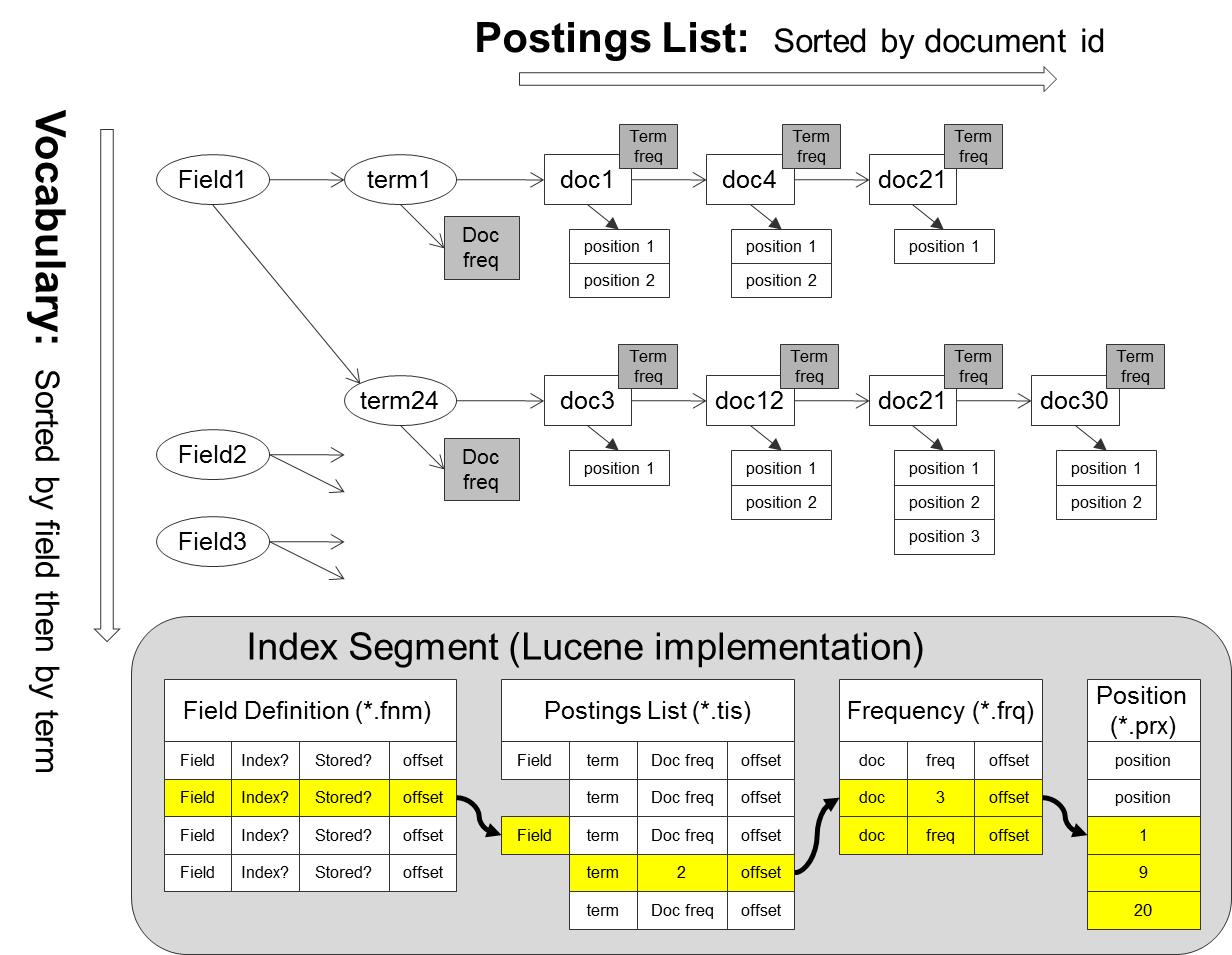
- Postings List
Indexing하는 과정에서 생성하게 되는 (Document별 Unique한 식별값인) Document ID들을 모은 List이다.
정렬은 Document ID별로 하여, List를 생성한다. - Vocabulary
각 Field별로 추출한 Term들의 집합 - Field
Term들을 묶은 집합 (Term들을 대표하는 개념이라기 보다는 document별로 공통으로 구분하는 데이터집합) - Term
Field에서 (tokenization에 의해) 추출한 word 또는 token - Doc Freq
해당 Term이 몇개의 Document에 존재하는가에 대한 빈도 - Term Freq
해당 Term이 각 Document내에 몇번 나타나는가에 대한 빈도 - position
해당 Term이 Field내에 몇번째 Term인지에 대한 값으로, 맨 앞에 존재하면 0 - offset
해당 Term이 Field내의 문자열 시작점부터 끝점까지의 값
[TF-IDF]
TF-IDF(Term Frequency - Inverse Document Frequency)는 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치이다. 문서의 핵심어를 추출하거나, 검색 엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도를 구하는 등의 용도로 사용할 수 있다.
[LSH]
Locality Sensitive Hashing 은 hashing 기반 방법으고 가장 널리 이용되는 ANNS(Approximated nearest neighbor search)이다. 정확한 k개의 최인접이웃을 찾는게 아닌 비슷한 최인접 이웃을 빠르게 찾기 위한 방법이다. 벡터 공간을 단순한 공간으로 분할해서 이해하는 vector quantization을 사용하고 hashing 기반 방법인 LSH가 가장 널리 이용되는 방법이다.
Locality Sensitive Hashing 은 Random Projection 을 이용하는 Approximated Nearest Neighbor Search (ANNS) 알고리즘입니다.
2. 텐서 플로우
텐서플로우는 구글이 개발한 머신러닝 프레임워크 오픈소스로, C++, Java 등에서 사용 가능하지만 대표적으로 파이썬에서 가장 많이 사용되고 있다. 여러 머신러닝과 인경신경망 관련 객체와 함수들이 API 형태로 구현되어 있다.
3. 인공신경망 기반 자연어 처리 모듈
[임베딩]
자연어 처리 과정 중 사람의 언어를 컴퓨터가 이해하기 위해 Vector 로 바꾸는 과정에 Embedding 방식을 사용한다.
자연어가 Vector 화 되기 때문에 사칙연산이 가능하고 벡터 공간에서 계산되는 LSH 알고리즘을 적용 할 수 있게 된다.
[KorQuad]
LG CNS 에서 만들고 배ㅐ포하는 KorQuad 데이터 셋을 이용한 모델을 참고한다. SQuaAD와 동일한 방식으로 구성되어 있다.
[BERT]
[BiDAF]
참고글
KorQuAD
AI NLP Challenge What is KorQuAD 2.0? KorQuAD 2.0은 KorQuAD 1.0에서 질문답변 20,000+ 쌍을 포함하여 총 100,000+ 쌍으로 구성된 한국어 Machine Reading Comprehension 데이터셋 입니다. KorQuAD 1.0과는 다르게 1~2 문단이 아��
korquad.github.io
웹페이지의 랭킹을 매기는 TF-IDF 법 - 미스터 SEO
TF-IDF 법은 문자 그대로 TF (term frequency)라는 지표와 IDF (inverse document frequency)라는 지표의 두 가지 지표를 이용한 알고리즘입니다.
mrseo.co.kr
https://blog.lael.be/post/3056
대용량 검색 처리를 위한 inverted index (역색인) 설명
#최종 수정 : 2017-03-22 – 내용과 예제를 보강하였습니다. 이 개념은 ElasticSearch 나 Apache Solr 를 다루기 위해 필수적으로 알아야 할 개념입니다. 라엘이의 한마디 : 역방향 인덱스(inverted index)는 원��
blog.lael.be
[블로터10th] 언론사가 알아야 할 알고리즘③ TF-IDF
포털 검색은 현대인의 일상이다. 매일 아침 ’핫‘ 이슈를 실시간 급상승 검색어를 통해 확인한다. 어떤 인물이 혹은 어떤 이슈가 대한민국의 관심을 주도하고 있는지 검색을 통해 발견하고 확�
www.bloter.net
AI Network_KR – Medium
AI를 위한 글로벌 컴퓨터 네트워크 구축.
medium.com
인공지능(AI) 언어모델 ‘BERT(버트)'는 무엇인가 - 인공지능신문
지난해 11월, 구글이 공개한 인공지능(AI) 언어모델 ‘BERT(이하 버트, Bidirectional Encoder Representations from Transformers)’는 일부 성능 평가에서 인간보다 더 높은 정확도를 보이며 2018년 말 현재, ...
www.aitimes.kr
심층 학습 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 심층 학습(深層學習) 또는 딥 러닝(영어: deep structured learning, deep learning 또는 hierarchical learning)은 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화(abstrac
ko.wikipedia.org
'ETC' 카테고리의 다른 글
| 🍺 BDD - Beer Driven Development (4) | 2020.06.18 |
|---|---|
| 🎓졸업과제 - 착수 보고서 (2) | 2020.06.03 |
| Notion으로 생산성 높이기 (0) | 2020.05.26 |
| MS-Power Apps 간단 후기 (0) | 2020.04.05 |
| 네이버 iOS 개발직군 지원자격 및 우대사항 분석 (0) | 2020.04.04 |




댓글