주제 : 질의응답 시스템을 위한 테이블 데이터 임베딩 및 어텐션 시각화
과제 목표
- 기계독해를 통해 사용자의 질문에 대해서 가장 알맞는 정답을 제시하는 질의응답 시스템을 개발한다.
- 위키피디아에 존재하는 모든 문서 중에서 일반 텍스트가 아닌 테이블 데이터에서 질문에 대한 정답을 찾나내는 것을 목표로 한다.
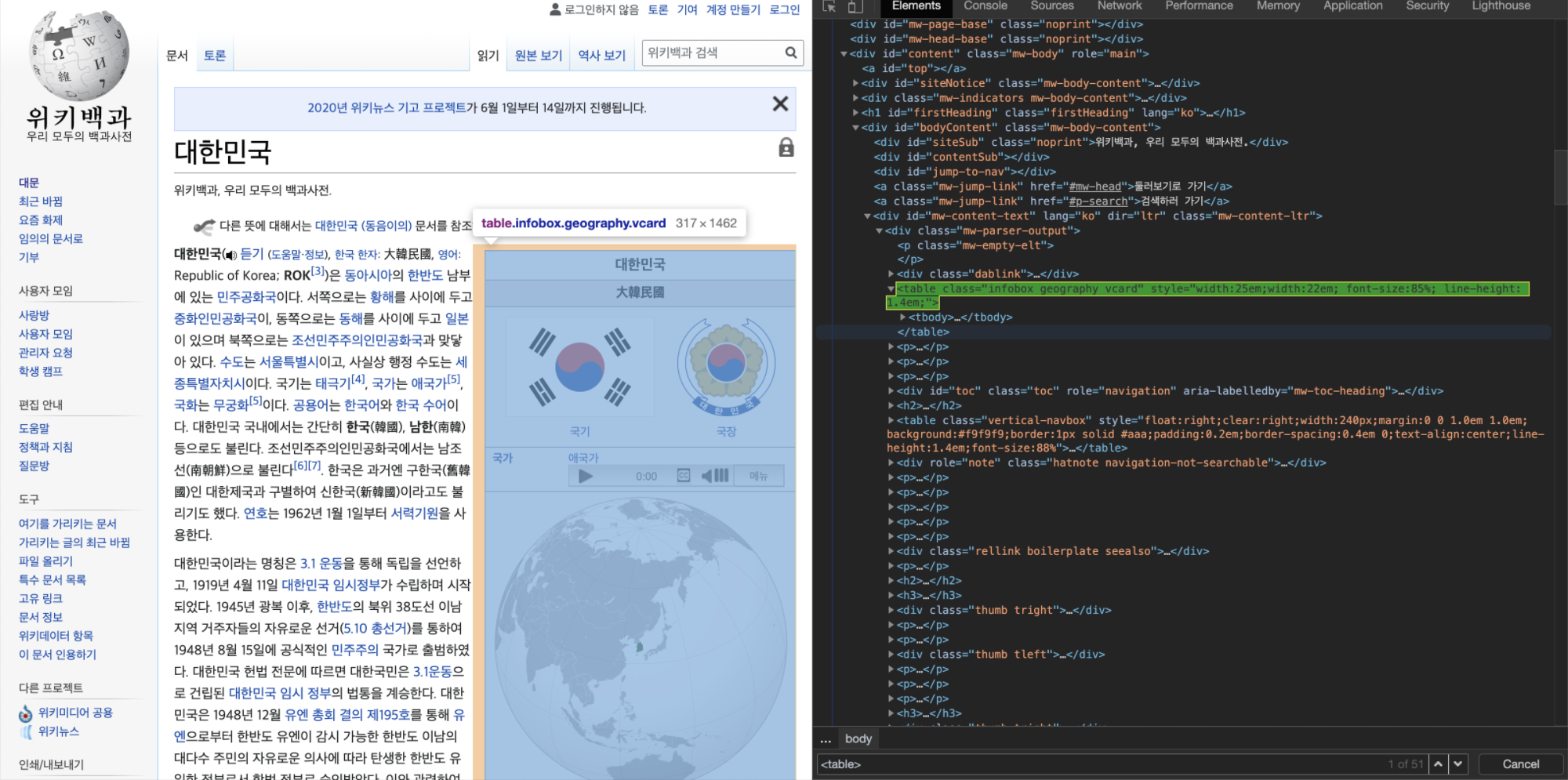
입력
: 정답을 포함하고 있는 위키피디아 문서
정답을 찾는 과정
- 위키피디아에 있는 여러 개의 문서 중에 어느 테이블에 정답이 존재하는지 결정한다.
- 해당 테이블에서 정답이 있는 셀을 결정한다.
- 셀에서 최종 정답을 추출한다.
대표적으로 사용될 기술
- BERT
- Memory Network
참고논문
http://koreascience.kr/article/CFKO201832073078709.page
TabQA : Question Answering Model for Table Data -Annual Conference on Human and Language Technology | Korea Science
Abstract 본 논문에서는 실생활에서 쓰이는 다양한 구조를 갖는 문서에 대해서도 자연어 질의응답이 가능한 모델을 만들고자, 그 첫걸음으로 표에 대해 자연어 질의응답이 가능한 End-to-End 인공신�
koreascience.kr
https://ai.googleblog.com/2020/04/using-neural-networks-to-find-answers.html
Using Neural Networks to Find Answers in Tables
Posted by Thomas Müller, Software Engineer, Google Research Much of the world’s information is stored in the form of tables, which can b...
ai.googleblog.com
WikiTableQuestions: a Complex Real-World Question Understanding Dataset - The Stanford Natural Language Processing Group
Natural language question understanding has been one of the most important challenges in artificial intelligence. Indeed, eminent AI benchmarks such as the Turing test require an AI system to understand natural language questions, with various topics and c
nlp.stanford.edu
http://cis.csuohio.edu/~sschung/CIS660/Stanford2017readingWikiForAnswering.pdf
https://ebbnflow.tistory.com/151
[BERT] BERT에 대해 쉽게 알아보기1 - BERT는 무엇인가, 동작 구조
● 언어모델 BERT BERT : Pre-training of Deep Bidirectional Trnasformers for Language Understanding 구글에서 개발한 NLP(자연어처리) 사전 훈련 기술이며, 특정 분야에 국한된 기술이 아니라 모든 자연어..
ebbnflow.tistory.com
http://freesearch.pe.kr/archives/4876
Attention API로 간단히 어텐션 사용하기 - from __future__ import dream
GluonNLP NLP쪽에서 재현성의 이슈는 정말 어려운 문제이다. 실제 모형의 아키텍처와 적절한 전처리 로직이 잘 적용 되었을때 성능이 도출되나 대부분 리서치에서는 전처리 로직에 대한 충분한 설�
freesearch.pe.kr
Memory Network
An Ed edition
reniew.github.io
https://github.com/ppasupat/WikiTableQuestions
ppasupat/WikiTableQuestions
A dataset of complex questions on semi-structured Wikipedia tables - ppasupat/WikiTableQuestions
github.com
- 표 데이터에 대해 자연어로 질의응답을 할 수 있는 기계학습 모델을 만든다.
- 기존의 방식으로는 Triple 형태로 지식 베이스를 구축하거나 DB화 하여 SQL 문법에 맞게 질의해야한다.
다양한 필드가 추가되거나 변경될 때 유지 보수 비용이 많이 들고 문법에 맞는 질의를 해야한다는 단점이 있다. - 표와 한국어 질의응답 쌍 데이터를 통해 표와 질문을 입력으로 받아서정답 셀을 찾아내는 모델 TabQA 를 구축했다.
- TabQA는 2차원 표 데이터를 입력 받아 질문에 대답하기 위한 임베딩 밥법과 여러 feature를 이용하여 정답의 위치를 찾아내는 학습 기반의 end-to-end 인공 신경망 모델로, 표의 행/열 구조를 그대로 이용한 질의가 가능하다.
- 주어진 테스트 셋에 대해 단일 모델 EM 스코어를 96.0%달성했다.
목차
- 데이터 임베딩
임베딩이란 자연어를 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련으이 과정 전체를 가리키는 용어입니다. 단어나 문장 각각을 벡터로 변환해 벡터 공간에 ‘끼워 넣는다(embed)’는 취지에서 임베딩이라는 이름이 붙었습니다. 컴퓨터가 자연어를 처리할 수 있게 하려면 계산 가능한 형식인 임베딩으로 바꿔주는 작업이 필요합니다. 임베딩은 컴퓨터가 자연어를 이해하도록 하는 첫 관문으로 자연어 처리 모델의 성능에 큰 역할을 담당합니다. - 데이터 어텐션 시각화
어텐션이란 NLP 에 있어서 중요한 메커니즘으로 모델이 출력 단어를 예측할 때 마다 전체 문장 대신 가장 관련성이 높은 정보가 집중된 입력 부분만을 사용하는 것입니다. 이 어텐션의 시각화를 통해 단어들의 상호간의 가중치를 확인 할 수 있습니다.
- BERT
BERT 는 구글에서개발한 자연어 처리(NLP) 사전 훈련 기술이며 모든 NLP 분야에서 좋은 성능을 내는 범용 Language Model 입니다. 여기서 사전 훈련 언어 모델이란 특정 과제를 수행하기 위한 모델의 성능은 데이터가 충분히 많다면 Embedding 이 큰 영향을 미칩니다. 이 중요한 Embedding 과정에서 BERT를 사용하는 것이고 특정 과제를 하기 전 사전 훈련 Embedding 을 통해 성능을 더 좋게 할 수 있는 언어 모델 입니다.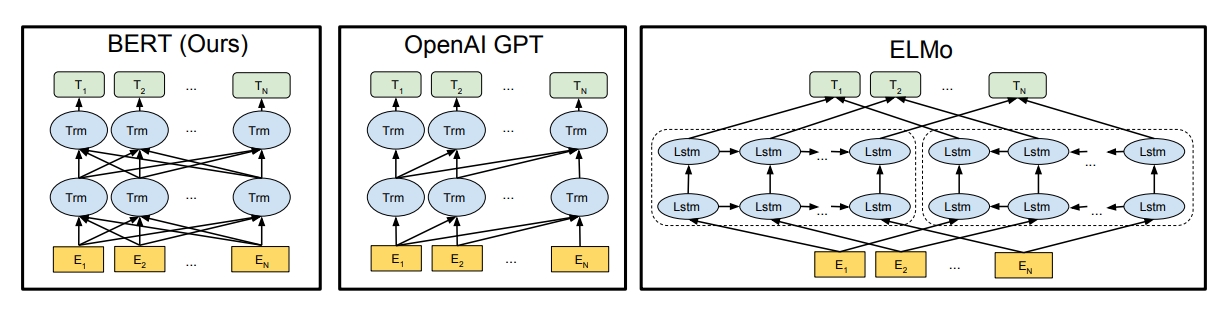
- Memory Network
memory를 이용해서 긴 text 에서 필요한 부분만 저장해서 사용할 수 있도록 하는 것 입니다. 대부분의 머신러닝 모델은 Long-term component를 잘 읽고 사용하지 못합니다. 예를 들어 전체 소설을 읽고 주제를 말하는 것과 같은 질문에 대답하기 어려운데 memory network 라는 모델을 통해 이를 해결할 수 있습니다. 핵심 아이디어로 머신러닝에서 효과적인 학습 전략과 Memory compenent 를 결합해서 사용하는 것 입니다. - 기계독해
기계독해는 주어진 문서와 문서에 대한 질문이 주어졌을 때 문서 내에서 답을 구하는 문제입니다. 기계독해는 2016년 SQuAD를 시발점으로 많은 모델과 데이터가 연구 및 공개되었습니다. 기계독해 모델이 질의응답 엔진에 직접적으로 적용이 가능합니다. 문서를 찾아주기만 하는 서비스인 검색을 넘어서 문서를 이해하고 원하는 정보를 꼭 집어서 찾아 줄 수 있는 서비스를 만들 수 있습니다. 기계독해를 통한 질의응답은 검색과 자연어 처리의 첨단 접점입니다. 기계독해 기반 질의응답은 속도가 느린 한계가 있습니다.
- 개발환경
- 개발 언어
Python, Kotlin, C++ - 개발 도구
PyCharm, Android Studio, VIsual Studio - 대상 시스템
WindowPC, Android Phone
- 개발 언어
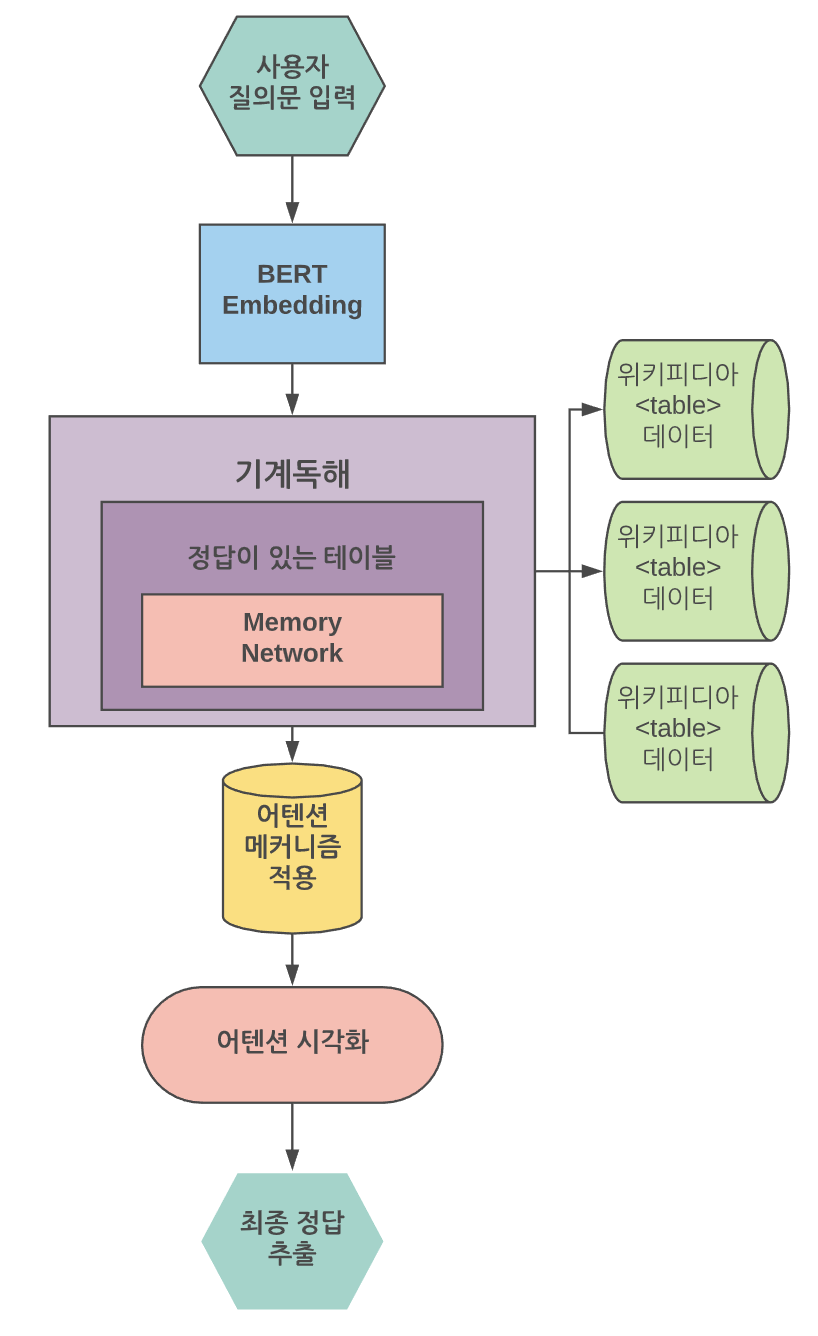
- 시스템 구성도
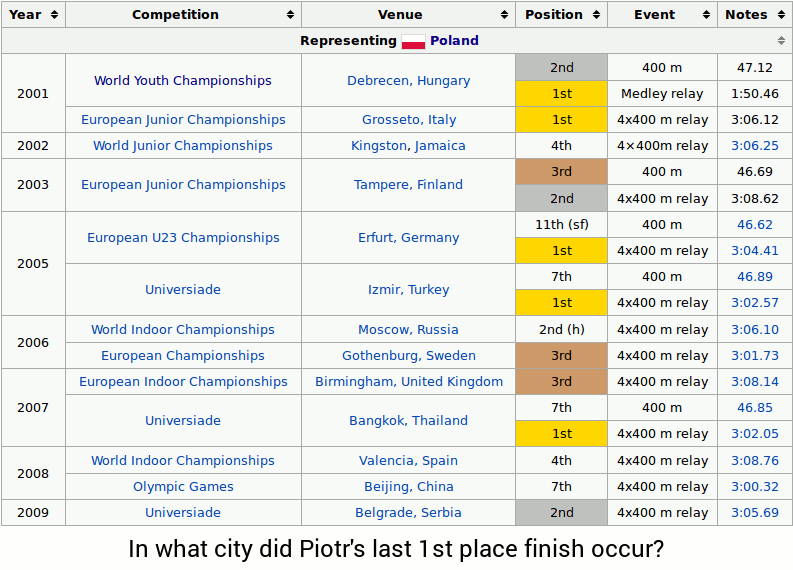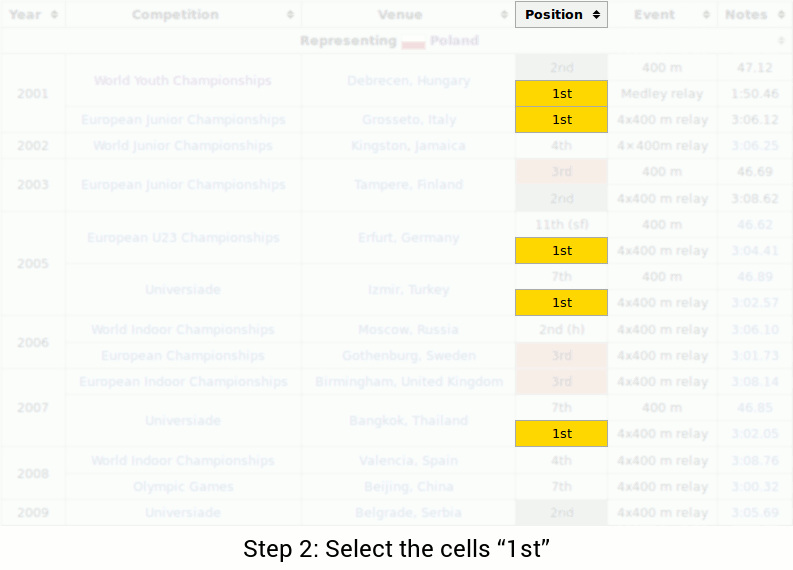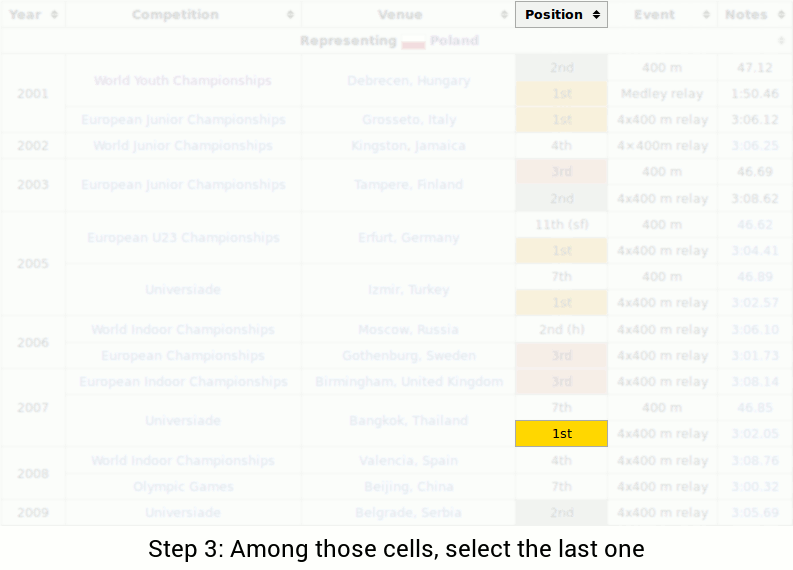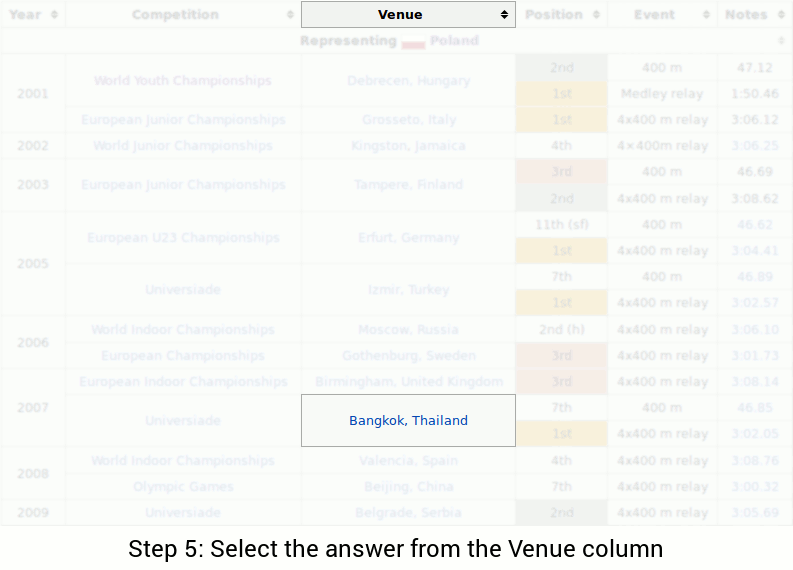
'ETC' 카테고리의 다른 글
| WWDC2020 미모지 만들기 (0) | 2020.06.25 |
|---|---|
| 🍺 BDD - Beer Driven Development (4) | 2020.06.18 |
| 🎓졸업과제 - 착수 보고서 준비와 설계부분 자료조사 (0) | 2020.05.31 |
| Notion으로 생산성 높이기 (0) | 2020.05.26 |
| MS-Power Apps 간단 후기 (0) | 2020.04.05 |




댓글