컴퓨터 구성요소
컴퓨터 구성요소를 이해하려면
- 각 요소들의 외부적 동작들(다른요소들과 교환하는 데이터와 제어 신호들에 대한 설명)
- 상호연결 조직의 사용을 관리하기 위해 필요한 상호 연결 조직과 제어에 대해 설명
컴퓨터 구성요소를 이해하게 되면
- 시스템 병목(System bottlenecks)
- 대체 경로들(alternate pathways)
- 부품 고장에 따른 시스템 결함의 정도 및 성능 향상 용이성 파악
폰 노이만 구조
- 데이터와 명령어는 읽기 쓰기가 가능한 기억장치에 함께 저장된다.
- 기억장치의 내용은 저장된 데이터의 형식에 관계없이 위치에 따라 주소를 지정할 수 있다.
- 명령어의 실행은 (별도의 수정이 없는 한) 한 개씩 순서대로 진행된다.
*hardwired program : 여러가지 형태로 결합된 작은 논리 회로 모듈처럼 산술 및 논리 연산, 특수 연산을 수행할 수 있는 회로를 구성하는 것의 결과로 나타나는 "프로그램"은 하드웨어 형태를 가지며 이것을 hardwired program 이라고 부른다.
(Sequence of arithmetic and logic functions)
*software : 새로운 프로그램을 수행 시킬 때 마다 하드웨어를 재구성 하는 대신 새로운 코드를 제공한다. 각 코드는 명령어이며 하드웨어의 한 부분이 각 명령어를 해석하여 제어 신호를 발생시키는 프로그래밍 기법.
(Instruction interpreter + General-purpose arithmetic and logic functions)
*I/O Component : 데이터와 명령어들이 시스템에 들어오기 위한 어떤 형태의 입력모듈. 임의의 형태를 가진 데이터와 명령어들을 받아들이고 그들을 시스템이 사용할 수 있는 내부 신호 형태로 변환한다. 결과 보고를 위한 출력 모듈의 형태도 가진다.
*기억장치(주 기억장치) : 명령어와 데이터를 일시적으로 저장해 둘 장소

CPU
- MAR(Memory Address Register) : 다음에 읽거나 쓸 기억 장소의 주소를 저장한다.
- MBR(Memory Buffer Register) : 기억장치에 저장될 데이터 혹은 기억장치로 부터 읽은 데이터를 일시 저장한다.
- I/O AR(Address Register) : 특정 I/O 장치를 지정한다.
- I/OBR(Buffer Register) : I/O 모듈과 CPU 사이의 데이터 교환을 위해 사용된다.
기억장치 모듈
- 주소가 순차적으로 지정된 기억 장소들의 집합
- 각 기억 장소에는 명령어 혹은 데이터로 해석될 수 있는 2진수 저장
I/O 모듈
- I/O 모듈은 외부장치 와 CPU 및 기억장치로 또 반대방향으로 데이터전송(일시 보관을 위한 내부 버퍼 소유)
컴퓨터의 기능(프로그램 실행의 주요 요소)
- 기본 기능 : 프로그램을 실행하는것
- 프로그램 : 기억장치에 저장되어 있는 명령어의 집합
- 프로세서 : 프로그램 내의 지정된 명령어들을 실행
명령어 처리
- instruction fetch : 프로세서가 기억장치로부터 한 번에 한 개씩 명령어를 읽어온다.
- instruction execution : 명령어를 실행한다.
*instruction cyle(명령어 사이클) : 한 개의 명령어 실행을 위해 필요한 과정
-fecth cycle + execution cycle
명령어 인출과 실행

- 프로세서는 기억장치로 부터 명령어를 인출한다.(전형적인 프로세서의 경우 PC가 다음 인출할 명령어의 주소를 가지고 있다.)
- 프로세서가 명령어를 인출 한 다음 PC의 내용을 증가시킨다(기억장치의 다음 위치에 저장되있는 명령어)
- 증가된 PC 에서 인출된 명령어는 IR(명령어 레이스터) 라고 불리는 프로세서 내부의 레지스터에 적재된다.
(명령어는 2진수 코드 형태를 가지고 있으며, 프로세서가 수행할 동작을 지정해준다.) - 프로세서는 명령어를 해석하고 그 결과에 따라 필요한 동작들을 수행한다.
명령어 동작의 종류
- 프로세서-기억창치 : 데이터는 프로세서 -> 기억장치 혹은 그 반대로 전송된다
- 프로세서-I/O : 프로세서와 I/O모듈 사이에 데이터를 전송 함으로써 외부->내부 혹은 내부->외부 로 데이터가 전송된다.
- 데이터 처리 : 프로세서는 데이터를 가지고 어떤 산술적 혹은 논리적 연산을 수행한다.
- 제어 : 어떤 명령어는 실행 순서를 변경시킨다.
--> 한 명령어는 이러한 동작들 중의 몇 가지가 결합된다.
예시)
- AC 에 프로세서 데이터 일시저장
- 명령어와 데이터 길이 16비트
--> 기억장치 한 저장소 16비트씩 저장할 수 있도록 구성 - 명령어 형식에서 연산 코드로 4비트 사용
--> 2^4=16가지의 연산코드(opcode) 지정가능
--> 2^16=4096(4K)개까지의 단어들에 대한 기억장치 주소 직접 지정 가능

프로그램 실행 예시 : 기억장치의 940번지의 내용을 941번지의 내용과 더하고 결과를 941번지에 저장
- 3번의 인출 사이클 + 세번의 실행 사이클

- PC가 첫번째 명령어의 주소인 300을 가지고 있다. 이 명령어(16진수로 1940)은 IR 로 적재되며 PC는 증가된다.
이 과정에서 MAR 과 MBR이 사용된다. - IR에 있는 첫 4비트(16진수로 1)은 AC가 적재될 것을 가르킨다. 나머지 12비트(16진수로 940)은 데이터가 적재되어올 주소 940번지를 지정한다.
- PC 301에 있는 다음 명령어 5941이 인출되고 PC가 증가된다.
- AC에 들어있던 내용과 941번지의 내용이 더해지고 결과가 PC에 저장된다.
- PC 302에 있는 다음 명령어 2941이 인출되고 PC 가 증가된다.
- AC의 내용이 941번지에 저장된다.
*특정 명령어의 실행 사이클은 한번 이상의 기억장치 참조를 포함한다
예시) PDP-11 프로세서의 ADD B,A
명령어의 상태

- Instruction address calculation / 명령어 주소 계산 : 다음에 실행될 명령어의 주소를 결정한다. (보통 직전 실행된 명령어 주소에 일정한 수를 더한다.)
예시) 명령어의 길이가 16비트이고 기억장치도 16비트 단어로 조직되어있으면 이전 주소에 1을 더한다.
명령어의 길이가 16비트이고 기억장치는 8비트 단어로 주소지정 하도록 조직되어 있으면 이전 주소에 2를 더한다. - instruction fetch / 명령어 인출 : 기억장치로 부터 프로세서로 명령어르 읽어온다.
- instruction operation decoding / 명령어 연산 해독 : 수행될 연산과 사용될 오퍼랜드의 형식을 결정하기 위해 명령어를 분석한다.
- operand address calculation / 오퍼랜드 주소 계산 : 연산이 기억장치나 I/O로 부터의 오퍼랜드를 필요로 할 경우 해당 오퍼랜드의 주소를 결정한다.
- operand fetch / 오퍼랜드 인출 : 오퍼랜드를 기억장치로 부터 인출하거나 I/O로부터 읽어온다
- data operation / 데이터 연산 : 명령어가 지정한 연산을 수행한다.
- operand store / 오퍼랜드 저장 : 그 결과를 기억장치에 저장하거나 I/O로 내보낸다.
인터럽트
명령어 사이클의 본질과 상호 연결 조직에서의 인터럽트의 의미를 이해한다.
인터럽트 :
- 처리 효율을 향상 시키기 위한 방법으로 제공
예시) 프로세서 보다 느린 외부 장치(프린터) 로 데이터를 전송할 때 프로세서는 대기하지 않고 다음 명령어를 실행한다. - 단순히 정상적인 프로그램의 흐름을 방해 하는것
- 사용자 프로그램은 인터럽트에 대비한 특수 코드 포함할 필요 없음
- 사용자 프로그램의 실행 연기와 다시 시작은 프로세서와 운영체제 담당
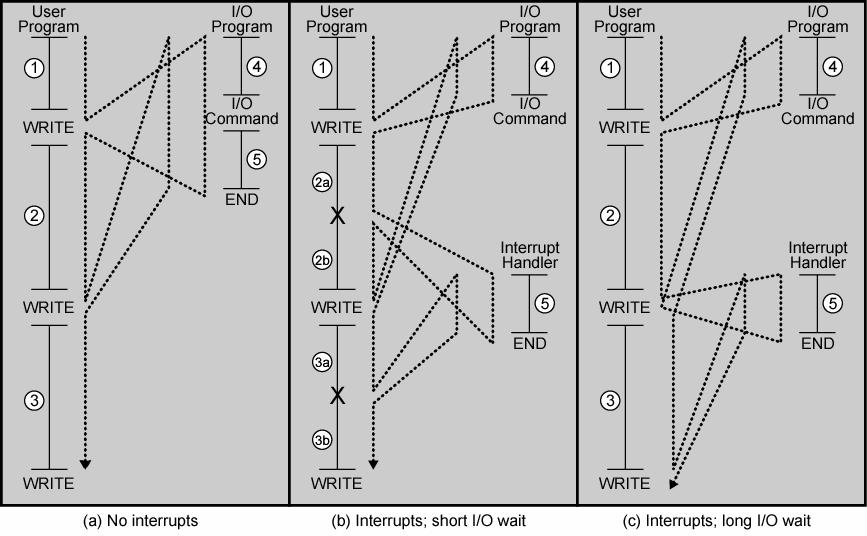
I/O 프로그램의 세가지 영역
- (코드부분) 4번 명령어 : 실제 I/O 동작을 준비하는명령어, 출력할 데이터를 버퍼로 복사하거나 장치 구동을 위한 명령 파라미터 준비
- (I/O 명령) 실제 I/O 명령 : 인터럽트를 사용하지 않을 땐 명령이 발생되면 I/O 장치가 필요한 기능을 수행할 때 까지 기다려야 함.
- 프로그램은 I/O동작의 완료 여부를 확인하기 위해 단순 검사 동작 반복 - (코드부분) 5번 명령어 : 동작을 종료하기 위한 명령어. 성공 혹은 실패 여부를 나타내는 flag 포함.
인터럽트의 종류
- Program
- TImer
- I/O
- Hardware Failture
인터럽트 사이클
- 프로세서는 인터럽트 신호를 조사하여 인터럽트 발생 여부 점검
- 인터럽트 X
- 프로세서는 인출 사이클로 돌아가 현재 실행 중인 프로그램의 다음 명령어 인출 - 인터럽트 O
- 현재의 프로그램 실행 중단, context 저장(다음 명령어의 주소:PC현재 내용, 프로세서의 현재 동작과 관련된 데이터 저장)
- 프로그램 카운터에 인터럽트 처리기(interrupt handler) 루틴의 시작 주소를 세트 - 인터럽트 O 이후 프로세서는 인출 사이클로 돌아가 interrupt handler의 첫 번째 명령어를 인출하여 인터럽트에 대한 서비스 시작
- 인터럽트 X
*인터럽트 처리기(interrupt handler) : 인터럽트를 발생한 I/O모듈을 찾아내고 그 I/O모듈로 데이터를 전송하기 위한 프로그램으로 이동. 인터럽트 처리기 루틴의 실행 종료시 프로세서는 이전에 실행 중단된 사용자 프로그램을 재시작.
*오버헤드(overhead) : 오버헤드는 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 · 메모리 등을 말한다. 예를 들어 A라는 처리를 단순하게 실행한다면 10초 걸리는데, 안전성을 고려하고 부가적인 B라는 처리를 추가한 결과 처리시간이 15초 걸렸다면, 오버헤드는 5초가 된다.
다중 인터럽트 처리방법
- 인터럽트를 처리하고 있는 중에는 인터럽트가 불가능 하도록 한다.
- 인터럽트 불가능 상태(disabled interrupt) : 프로세서가 인터럽트 요구 신호를 무시할 수 있는 상태
- pending 으로 있다가 인터럽트 가능 상태가 되면 프로세서에 의해 처리
- 인터럽트가 순차적으로 처리됨
단점 : 상대적 우선순위, 시간적 위급성 고려X - 인터럽트의 우선순위를 정하고 우선순위가 높은 순서대로 처리
- ISR(interrupt service routine)
I/O 기능
- I/O 모듈 : 프로세서와 직접 데이터 교환 가능
- 프로세서는 특정 I/O 모듈에 의해 제어되는 장치를 구분하기 위해 주소를 사용
- DMA(direct memory access) : I/O 모듈이 기억 장치와 직접 데이터를 교환할 수 있도록 읽기 쓰기 권한을 I/O 모듈에 부여
상호 연결 조직
컴퓨터 구성
- 프로세서
- 기억장치
- I/O 장치
사이에서 서로 통신이 필요함.
컴퓨터는 기본 모듈들의 network라고 생각해도 됨.
이 모듈들을 연결하기 위한 경로(path) 가 필요함
이 경로들의 집합 --> 상호연결 조직(interconnection structure)
서로 교환될 데이터의 정의
- 기억장치 : 전형적으로 동일한 길이를 가진 N개의 단어로 구성, 각 단어에는 고유의 주소가 할당, 읽기 쓰기 동작, 주소에 의해 위치 지정
- I/O 모듈 : 기능적(읽기쓰기)으로 기억장치와 유사. 한개의 I/O 모듈은 한개 이상의 외부장치들을 제어할 수 있음. port(외부 장치와 연결된 인터페이스)에 각각의 고유의 주소 부여. 프로세서로 인터럽트 신호 보낼 수 있다
- 프로세서 : 명령어들과 데이터를 읽어들이고 처리한 데이터를 내보내며 시스템의 전반적인 동작을 제어하기 위한 제어신호를 사용, 인터럽트 신호 받음
전송의 유형
- Memory --> Processor
- Processor --> Memory
- I/O --> Processor
- Processor --> I/O
- I/O --> Memory
- Memory --> I/O
상호 연결 조직 예시
- BUS, 다중BUS
- 점대점 상호연결 조직(패킷화된 데이터 전송-packetized data transer)
버스 상호연결
BUS
- 시스템 구성요소 상호연결의 가장 중요한 수단
- 두개 혹은 그 이상의 장치들을 연결하는 통신 경로
- 공유 전송 매체(shared transmission medium)
- 여러개의 장치들이 버스에 연결되어 있고 그들 중 한 장치가 전송한 신호를 버스에 접손된 다른 모든 장치가 수신 가능
- 한번에 한 장치만 성공적으로 전송 가능
- 여러개의 통신 경로 혹은 선으로 구성
- 각 선은 2진수 1과0으로 표현되는 한 비트의 신호르 전송 가능
- 한개의 신호 선을 통해 2진수 비트가 연속적으로 전송됨
- 여러개의 선들로 이루어진 버스는 병렬로 (동시에) 전송가능
예) 8비트 단위 데이터는 8개의 버스선을 통해 한번에 전송
System Bus
- 컴퓨터의 주요 구성요소(프로세서, 기억장치, I/O)를 연결하는 버ㅅ
- 한개 혹은 그 이상의 시스템 버스가 사용됨
- 50~100개의 선들로 구성
- 선들은 기능에 따라 분류
- 데이터 선
- 주소 선
- 제어 선
- (전력 분배 선)
데이터 선(버스)
- 시스템 모듈 간의 데이터 이동 경로 제공
- 32 ~ 수백개의 선으로 구성
- 선의 수를 데이터 버스의 폭(width)라 부른다.
- 버스의 폭은 한번에 전송할 수 있는 비트의 수를 결정한다.
예) 데이터 버스 폭이 8비트, 각 명령어의 길이가 16비트 --> 프로세서는 명령어를 읽어오기 위해 기억장치에 두번 access 해야함
주소 선
- 데이터 버스로 전달되는 데이터의 근원지나 목적지를 지정함
예) 기억장치에서 한 단어의 데이터를 읽으려 할 때 주소선들에 원하는 단어의 주소를 실음 - 주소버스의 폭은 시스템의 최대 기억장치 용량을 결정
- I/O 포트를 지정하기 위해 사용됨
상위 비트들 : 버스에 연결된 모듈을 선택
하위 비트들 : 모듈 내의 기억장치의 위치, I/O포트를 선택하느데 사용
예) 8비트 버스 상에서 주소 01111111이하는 128개의 단어로 구성된 기억장치 모듈(0)의 위치를 지정, 10000000이상은 I/O모듈(1)에 접속되어 있는 장치들을 지정
제어 선
- 데이터 선들과 주소 선들의 사용을 제어하기 위해 사용
- 제어신호는 시스템 모듈들 사이에 명령과 타이밍 정보를 모두 전달
- 타이밍 신호 : 데이터 + 주소 정보의 유효성
- 명령 신호 : 수행할 동작 결정
제어신호에 포함된 기능
- 기억장치 쓰기 : 버스에 있는 데이터를 주소 지정된 위치에 쓴다.
- 기억장치 읽기 : 주소 지정된 기억 장소의 데이터르 버스로 읽어낸다.
- I/O 쓰기 : 버스에 있는 데이터를 주소 지정된 I/O 포트로 출력
- I/O 읽기 : 주소 지정된 I/O 포트에서 데이터르 읽어 버스에 싣는다.
- 전송확인(transfer ACK)
- 버스 요구 : DMA를 위해 모듈이 버스 사용을 요구하고 있는 상태
- 버스 승인 : 버스 요구한 모듈에게 허가되었다는 걸 가리킴
- 인터럽트 요구 : 인터럽드가 대기하고 있는 상태
- 인터럽트 확인 : 대기하던 인터럽트가 인식된걸 통보
- 클락 : 동작들의 동기화
- 리셋 : 모든 모듈을 초기화
버스의 동작-데이터 전송
- 버스의 사용권을 얻는다.
- 버스를 통하여 데이터를 전송한다.
버스의 동작-데이터 수신
- 버스의 사용권을 얻는다.
- 버스를 통하여 적절한 제어선과 주소선을 통해 다른 모듈에게 요구 신호 전달
- 해당 모듈이 데이터 전송해 줄떄까지 대기
점대점 상호연결
버스 --> 점대점 상호연결 변화의 이유
- 넓은 동기식 버스들의 주파수가 높아짐에 따라 발생된 전기적 제약(electrical constraints)
- 멀티코어의 출현으로 다수의 프로세서들과 큰 기억장치가 하나의 칩에 들어가게 되면서 버스 데이터율을 증가시키거나 버스 지여을 줄이는데 어려움이 커짐
점대점 상호연결의 장점
- 지연이 적다
- 데이터율이 높다
- 선형성(Scalability)가 높다.
인텔의 QuickPath Interconnect(QPI) 의 장점 및 p2p interconnection 방식의 주요 특성
- 다중 직접 연결(multiple direct connections)
- 시스템 내의 여러 구성요소들이 다른 요소와 직접 연결된다. - 계층화된 프로토콜 구조
- TCP/IP 기반 데이터 네트워크와 같이 제어 신호들을 계층화된 프로토콜 구조를 이용한다. - 패킷화된 데이터 전송
- data stream 이 아닌 일련의 패킷으로 제어 헤더와 오류 제어 코드를 포함한다.

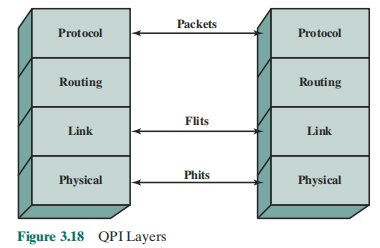
QPI 의 4-계층 프로토콜 아키텍쳐
- 물리적 : 1과 0을 전송받는데 필요한 회로나 논리뿐 아니라 신호를 전달하는 실제 회선.
전송단위는 20bit(Phit) - 링크 : 신뢰성 높은 전송과 흐름제어를 책임짐. 전송
전송단위는 80bit(Flit) - 라우팅 : 패킷들이 페블릭을 지나가도록 통제하기 위한 프레임워크 제공
- 프로토콜 : 장치들 간에 데이터 패킷들을 교환하는데 필요한 상위 규약
패킷 = 여러개의 Flit 으로 구성
QPI 물리적 계층
- 84가지의 별도 링크로 구성됨
- 각 데이터 통로는 한 번에 한 비트의 데이터를 전송하는 한짝의 선으로 구성 : lane
- 각 방향에 20개의 데이터 lane 존재
- 각 방향에 clock lane 추가
- 한 방향으로 병렬 20비트 전송 가능(1 phit)
- 저전력 차등 시그널링 적용
- 복수레인 분포
*균형 전송 : 신호들은 한 전도체로 흘러가고 다른 전도체로 되돌아오는 전류로서 전송됨, 한 선은2진수 1과 다른 선은 2진수 0과 관련.
*차등 시그널링 : 송신기는 내보낼 논리 레벨에 따라 어느 한 선 혹은 다른 선으로 적은 전류를 주입해 저항을 통하여 수신측으로 흘러가며 다른선을 통하여 반대방향으로 되돌아옴.
*복수레인 분포 : 80비트 Flit 와 20비트 Phot간의 변환을 책임
QPI 링크 계층
- 흐름 제어 기능 : 수신기가 데이터를 처리하고 들어오는 데이터를 위해여 버퍼를 비우는 것보다 더 빨리 데이터를 보냄으로써 전송되는 QPI 항목이 수신되는 QPI를 덮어씌우지 않도록 보장하기 위해 필요하다.
- Credit 방식 사용 - 오류 제어 기능 : 물리적 계층에서 전송되는 비트가 전송 과정중 노이즈에 의해 변경되는 오류들을 검출하고 복구하여 더 높은 계층들을 비트 오류로 부터 분리시키기 위해 필요하다.
*Credit 방식 : 초기화 동안 sender는 receiver로 Flit를 보낼 수 있는 credit 을 여러개 가지게 되고 receiver로 보낼 때 마다 credit의 count를 감소시킨다. 수신기의 버퍼가 비게될 때마다 credit을 되돌려 준다.
*오류 제어 기능 상세는 책참고 p.109
QPI 라우팅 계층
- 패킷이 이용할 시스템 사오연결 경로를 결정하기 위해 사용
- routing table은 펌웨어에 의해 결정(패킷이 흘러갈 수 있는 통로들을 포함)
QPI 프로토콜 계층
- 패킷이 전송의 단위로서 정의됨
- packet contents definition은 다양한 시장 세그먼트 요구를 충족시킬 수 있게 융통성있게 표준화
- 캐시 일관성 프로토콜
- 패킷 : 캐시로 보내지거나 캐시로부터 오는 한 블록의 데이터
*캐시 일관성 프로토콜 : 여러 캐시들에 저장된 주기억장치 값들이 일관성을 가지도록 보장해줌
PCI Express
Peripheral Component Interconnection
- 주변장치 버스로서의 기능을 할 수 있는 고대역폭 프로세서-독립적 버스(high-bandwidth processor-independent bus)
- 고속 I/O 서브시스템(네트워크 인터페이스, 디스크 제어, 그래픽 디스플레이 접속기) 에 대해 더 높은 시스템 성능 제공
PCI 물리적 및 논리적 아키텍쳐
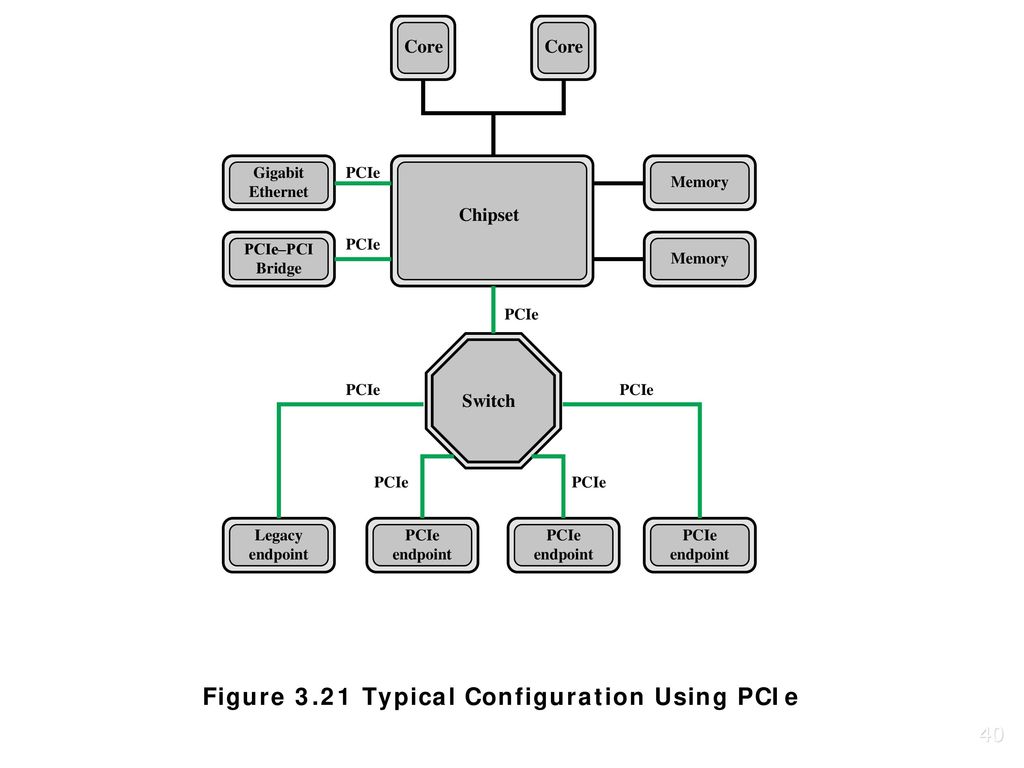
- Chipset(host bridge)
- Root complex
- PCIe링크와 접속되는 장치 유형
- 스위치
- PCIe endpoint
- Legacy endpoint
- PCI/PCI 브리지

- PCIe 프로토콜 아키텍쳐
- 물리적 : 0과 1의 전송 및 수신에 필요한 신호를 운반하는 실제 회선
- 데이터 링크 : 신뢰성 있는 전송 및 흐름 제어를 책임, DLL에 의해 생성되고 소모되는 데이터 패킷들은 데이터 링크 계층 패킷(DLLPs)라고 부름
- 트랜잭션 : 데이터 전송 매커니즘을 적재/저장하는데 사용되는 데이터 패킷들을 생성하고 소모하며, 링크 상의 두 요소들 사이에서 패킷들의 흐름 제어 관리. TL 에 의해 생성되고 소모되는 데이터 패킷들은 트랜잭션 계층 패킷(TLPs)라고 부름
PCIe 물리적 계층
- QPI 와 유사하게 점대점 구조
- 여러개의 양방향 레인들로 이루어짐(QPI 는 한방향)
- 레인에서 각 방향은 한쌍의 회선들 간의 differential signaling 에 의해 이루어짐
- 1, 4, 6, 16, 32 개의 레인들을 제공
- multilane distribution 기술 사용
- QPI와 달리 비트 스트림을 동기화 시키기 위해 클록을 사용하지 않음(다른 신호 목적으로만 사용)
- 수신기와 송신기의 동기화를 위해 transmitter와 동기화 되는 수신기에 의존
- Scrambling : 전송될 비트의 수를 증가시키지는 않으며 데이터가 임의로 나타나게 해주는 mapping 기술
- encoding : 2비트 블록의 sync header를 추가시켜 130비트 블록으로 매핑
PCIe 트랜잭션 계층
- 그 위의 소프트웨어로부터의 읽기 및 쓰기 요구를 받아들이고 링크계층을 경유하여 목적지로 전송을 위한 요구 패킷을 생성
- 주소 공간 및 트랜잭션 유형
- 기억장치 : 시스템 주기억장치, PCIe I/O장치 등
- I/O : regacy I/O장치들의 주소지정에 사용하기 위해 예약된 주소영역 이용
- 구성 : TL로 하여금 I/O장치들과 연관된 configuration registers을 읽고 쓸 수 있게 해줌
- 메시지 : 인터럽트, 오류 처리, 및 전력관리에 관련된 제어 신호를 위한 것
- TLP 코어의 필드
- 헤더 : 패킷 유형, 라우팅 정보, 수신기에 필요한 정보
- 데이터 : 4096바이트까지의 데이터 필드가포함될 수 있음
- ECRC : 선택적 end to end CRC필드는 목적지 TL 계층으로 하여금 TLP 헤더 및 데이터 부분 오류 검사 할 수 있게함
PCIe 데이터 링크 계층
- 데이터 링크 계층 패킷
- 트랜잭션 계층 패킷 처리
3.1 폰노이만 구조의 세 가지 핵심 개념들을 설명하라.
- 데이터와 명령어는 읽기와 쓰기가 가능한 기억장치에 함께 저장된다.
- 기억장치의 내용은 저장된 데이터의 형식에 관계없이 위치에 따라 주소를 지정할 수 있다.
- 명령어의 실행은 (별도의 수정이 없는 한) 한 개씩 순서대로 진행된다.
3.2 I/O 주소 레지스터 및 I/O 버퍼 레지스터 간의 차이점을 설명하라.
- I/O 주소 레지스터 : I/O 장치의 주소를 지정
- I/O 버퍼 레지스터 : I/O 모듈과 CPU 사이의 데이터 교환할 때 데이터를 일시 저장함.
3.3 인터럽트를 불가능하게 하는 방식의 단점은 무엇인가? 적절한 예를 들라.
- 상대적 우선순위 혹은 시간적 위급성을 고려하지 않는다는 점, 통신선에 입력이 도착하면, 다음 데이터를 받기 위한 공간을 비워주기 위하여 그 데이터의 입력 동작은 신속히 처리되어야 한다. 먼저 수신된 데이터는 다음 데이터가 수신될 때까지 처리되지 않으면 잃어버릴 수도 있다.
3.4 어떤 유형의 전송들이 컴퓨터의 상호연결 조직(예: 버스)을 지원해주는가?
- Memory --> Processor
- Processor --> Memory
- I/O --> Processor
- Processor --> I/O
- I/O --> Memory
- Memory --> I/O
3.5 QPI 프로토콜 계층들을 열거하고 간략히 정의하라
- 물리적 : 1과 0을 전송받는데 필요한 회로나 논리뿐 아니라 신호를 전달하는 실제 회선.
전송단위는 20bit(Phit) - 링크 : 신뢰성 높은 전송과 흐름제어를 책임짐. 전송
전송단위는 80bit(Flit) - 라우팅 : 패킷들이 페블릭을 지나가도록 통제하기 위한 프레임워크 제공
- 프로토콜 : 장치들 간에 데이터 패킷들을 교환하는데 필요한 상위 규약
패킷 = 여러개의 Flit 으로 구성
3.6 PCIe 프로토콜 계층들을 열거하고 간략히 정의하라.
- 물리적 : 0과 1의 전송 및 수신에 필요한 신호를 운반하는 실제 회선
- 데이터 링크 : 신뢰성 있는 전송 및 흐름 제어를 책임, DLL에 의해 생성되고 소모되는 데이터 패킷들은 데이터 링크 계층 패킷(DLLPs)라고 부름
- 트랜잭션 : 데이터 전송 매커니즘을 적재/저장하는데 사용되는 데이터 패킷들을 생성하고 소모하며, 링크 상의 두 요소들 사이에서 패킷들의 흐름 제어 관리. TL 에 의해 생성되고 소모되는 데이터 패킷들은 트랜잭션 계층 패킷(TLPs)라고 부름
Computer architecture Chapter 3 Review Questions
List and briefly define the PCIe protocol layers. PCI 익스프레스(PCI Express)는 2002년 PCI SIG가 책정한 입출력을 위한 직렬 구조의 인터페이스이며 인텔 주도하에 만들어졌다. 공식적인 약어로 PCIe로 표기..
haningya.tistory.com
'Computer Science > Computer Architecture & Organization' 카테고리의 다른 글
| CA & CO Chapter 4 practice problem (5) | 2020.04.21 |
|---|---|
| CA & CO Chapter 3 practice problem (0) | 2020.04.17 |
| CA & CO Chapter 1 기본 개념과 컴퓨터 발전과정 (3) | 2020.04.15 |
| ISA 어셈블리 코드 해석하기 (0) | 2020.03.26 |
| 무어의 법칙 (0) | 2020.03.26 |




댓글